VSCodeのRemote-ContainerでPython Tools serverがクラッシュする
The Python Tools server crashed 5 times in the last 3 minutes. The server will not be restarted.
Remote-Containerで起動した環境でPythonの補完機能を使いたかったのだが,上のエラーが毎回出てしまいます.
ネットの記事を見ると,extensionsのフォルダからms-python.python*を削除しなさい.ということが言われているが,これをRemote-Containerを起動するたびにやるのは面倒.
(それにその方法では解決しなかった)
解決方法
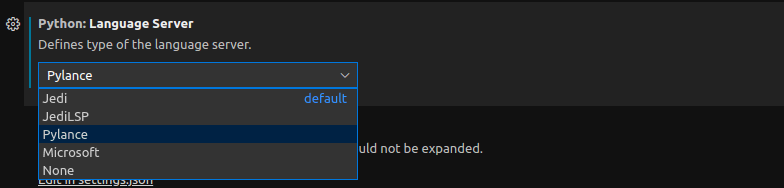
File -> Preferences -> Settings -> Extensions -> Python -> "Python: Language Server".
の設定を開く.
タブが出てくるので,Pylanceを選択する.
そして,リモートのコンテナ上にms-python.pythonだけではなく,ms-python.vscode-pylanceがインストールされているかを確認します. 参考までに,devcontainer.jsonのextensionsを載せておきます.
"extensions": [
"ms-python.python",
"ms-python.vscode-pylance",
]
この状態でRemote-Containerを起動するとちゃんと起動する.
結論
Thank you the discussions in the github issue!!!
画像に応じたCNNの受容野学習(Deformable Convolutional Networks)
Deformable Convolutional Networks
ICCV oral paper 2017 [J. Dai+, 2017]
ざっくり
- CNNの受容野(畳み込みをする範囲)を画像ごとに変更するDeformable Convolutional Networksを提案
- 従来のCNNにおける,(k x k)近傍の固定された受容野に対して,より洗練された畳み込みが可能に
緑が注目点で,赤が畳み込みの対象

Introduction
視覚の認識タスクにおいて、物体のスケールやポーズ、視点、歪み対してロバストな認識をすることは重要である。 従来手法では、データとCNNの制約からロバスト性に問題があった。
データの問題
大きく2つの方法によってロバストな推定器の実現が試みられていたが、問題が存在する。
- データの多様性をaugmentationなどによって増やす。モデルのサイズを大きくする。
- 欠点: データが大規模になる、モデルが巨大になる。
- 変形に対して不変な特徴量やアルゴリズム、例えばSIFTやmax-poolingなどを用いる
- 欠点: hand-craftedである
CNNの問題
CNNの畳み込み演算やPooling演算は固定された位置に対する処理であるため、幾何的な変形に対し強く影響を受けてしまう。
 (from: https://jifengdai.org/slides/Deformable_Convolutional_Networks_Oral.pdf)
(from: https://jifengdai.org/slides/Deformable_Convolutional_Networks_Oral.pdf)
同じ層の受容野(入力の範囲)の形と大きさが同じ。これは物体の意味論的な認識タスクではおかしい。 事前にBounding boxを用意するR-CNNの手法も適切ではない。
提案
普通の畳込みに学習可能な2Dオフセットを導入
RoI Poolingのビン位置に学習可能なオフセットを導入
関連手法
関連手法に Active Convolutional Network というものも存在する [Y. Jeon+, CVPR'17]。
これは 層ごとに固定のConvolutionのoffset を学習するというもの。
 層ごとにConvolutionの受容野が異なっていることがわかる。
層ごとにConvolutionの受容野が異なっていることがわかる。
Deformable Convolutional Network
Active Convolutional Networkに対し、Deformable Convolutional Netoworkは、全画像で一貫したoffsetではなく、 offsetを出力するConvolution Layer を導入、画素に応じたオフセットを推定する。

実際の結果が次図、緑点が注目点なのだが、それぞれに対して全然違うoffsetが算出されている。
そして、物体のスケールをよく捉えており、認識に必要な情報を効率よく捉えていることがわかる。

Eigen::Matrixのpybind11での使い方
Eigenではデフォルトで行列をFortranのようにCol Major方式で扱っている. この方式では,Row Major方式を採用しているpython numpy arrayとの連携で参照渡しをする際に問題が発生する.
そのため,C++で使うEigenのMatrixをRowMajorに変更する必要がある.
template <typename T> using RMatrix = Eigen::Matrix<T, Eigen::Dynamic, Eigen::Dynamic, Eigen::RowMajor>;
これをC++プログラムの最初に書けばいい.
なお,Vectorを扱う際はそもそもRow MajorとCol Majorで違いがないため,通常の使い方で構わない.
http://eigen.tuxfamily.org/dox/TopicFunctionTakingEigenTypes.html#TopicUsingRefClass
状態推定のためのLie群上の最適化3
しれっとタイトル少し変えていますが、そろそろ続き書きます。
前回のあらすじ
Lie代数の性質
今回は,Lie群上での要素の移動を接空間上で定義する和と差の演算について,さらにLie群上の点に対する接空間からLie代数の要素への変換を表すAdjoint(随伴表現)について説明します.
和と差の演算
これから和と差を,接空間上でのLie群上の要素の間の移動に関して定義することにします.
と
をLie群上の要素とします.
まずは,この二つの要素の移動の差分を接空間上の差として定義することを考えます.
この移動の差の定義には,
の2種類が考えられます.
図にすると次のようなイメージです.
前者の定義方法で得られた差分は単位元における接空間上で定義され,後者の定義方法で得られた差分はにおける接空間上で定義されることになります.

前者1.の差の定義方法(図だと上側の経路で定義されたを計算する演算)は
と表記されます.
rightとついているのは,Lie群要素の右に移動量があるからですね.
ここでは点
の接空間で定義された移動量
で
を移動させる,
の逆の演算として定義されています.
もう一つの定義として,後者2. の差の定義方法(図だと下側の経路で定義されたを計算する演算)は
と表記されます.
Adjoint (随伴表現)と随伴行列
さて,あるについて,2種類の移動量の定義方法をもって,
と
を定義しました.
この定義式から次のような等式が成り立ちます.
この式はまさに,上の図における2パターンの移動の到着地点が一致している様子を表しています.
この式から,
となることが分かります.(最後の式変換は前章ので紹介した性質を使っている)
この式を見ると,ある点における接空間の要素
を単位元における接空間(つまりLie代数)の要素
へ変換する操作を表していることが分かります.
Adjoint (随伴表現)
この操作を演算として定義します.
の点
におけるAdjoint(随伴表現)とは,
のような演算で,
となるようなもののことである.
Adjointには次のような性質がある.
Adjoint matrix(随伴行列)
は線形写像である.つまり,行列で表現できる!
上で定義したAdjointは接空間から接空間への写像であったが,実数の行列の演算として定義するために,接空間の係数ベクトル間の写像として定義します(
も線形演算だったので,
も線形写像となるのでこのようなことができる).
性質として次のようなものがあります.
これで,Lie群の要素をLie代数の中で足したり引いたりする操作が定義できました. さらに,Adjointによって任意のLie群の要素に対する移動をLie代数の中で演算することも可能になりました.
次の投稿ではついに,Lie群上で動く関数のLie群要素での微分を定義していきます. Lie群上の最適化をLie代数上で定式化することにだいぶ近づいてきました.
ユーザ型をEigen::Matrixへ変換するoperatorがうまく働かない
問題
次のようなコードを書いた.
ubuntu 16.04
struct pose { explicit operator Eigen::Matrix4f () const { Eigen::Translation3f translation(x, y, z); Eigen::AngleAxisf rotation_x(roll, Eigen::Vector3f::UnitX()); Eigen::AngleAxisf rotation_y(pitch, Eigen::Vector3f::UnitY()); Eigen::AngleAxisf rotation_z(yaw, Eigen::Vector3f::UnitZ()); return (translation * rotation_z * rotation_y * rotation_x).matrix(); } };
姿勢情報(x,y,z,roll,pitch,yaw) を剛体変換行列へ変換するoperatorを実装したのだが,思ったように使えなかった.
pose p; auto m = static_cast<Eigen::Matrix4f>(p); // compile error!!!
error: no matching function for call to 'Eigen::Matrix::_init1(const pose&)'
EigenのMatrixはコンストラクタによる初期化じゃなくてinitっていう関数へ置き換えられている...? それが何らかの理由でoperatorの呼び出し優先度よりも高くなってしまっているみたい.
理由
https://forum.kde.org/viewtopic.php?f=74&t=137768
Eigenのバージョン3.3では,Eigen::Matrixについて次のようなコンストラクタが定義されているみたい.
template <typename T> explicit Matrix(const T& x) {...}
これによって static_cast<Eigen::Matrix4f>(p) に対応する呼び出しがこのコンストラクタになってしまう.
解決策1(バージョン変更)
c++ - Conversion operator in Eigen - Stack Overflow
どうやらバージョンの問題らしい.
ubuntu 16.04でインストールしたもののバージョンが3.2.92だったが,3.2.6を使うとよいらしい.
解決策2 (明示的なキャストをやめる)
Eigen::Matrix4f m = p;
こうすると,operatorの方がきちんと呼ばれる.ただし,explicitは外しておく必要がある.
struct pose { operator Eigen::Matrix4f () const {...} };
しかし文法が変わってしまうので,テンプレートパラメータとしてEigen::Matrix4fを渡したときに少し困る.
これは,Eigen用の特殊化をするか,Eigen Matrix自体をラップするラッパークラスを作るような解決策が考えられる.
Eigenの演算がすごく重たい
あるプログラムを書き換えていたら,Eigenの演算が1000倍遅くなってしまった.
原因は,コンパイラ最適化オプションを最適化なしにしていたから.
add_compile_options(-std=c++17 -O2 -Wall)
としたら1000倍ぐらいの速度で演算してくれるようになった.
(-O2が抜けてた)
https://eigen.tuxfamily.narkive.com/Uzv4b3Sv/eigen-3-is-extremely-slow
Eigenコミュニティでも言われていたことだったみたいだけど,テンプレートの演算にとても時間がかかるから最適化オプションは必須らしい.
あーーー解決してよかった
VSCodeのC/C++ Intellisenseで#includeがどうしても解決しない
VSCode のC/C++ intellisense で自作ライブラリの#includeを行うとき,どうしても"configurationProvider 設定によって提供された情報に基づいて..."というエラーが発生して,ヘッダファイルをインクルードしたことにできなかった.
god_library/
┣ folder1/
│ └ foo1.h
└ folder2/
└ foo2.h
foo1.hからfoo2.hをインクルード (#include "folder2/foo2.h") するときにエラーが出た.
もちろん,c_cpp_propereties.jsonはしっかりと ${workspaceFolder} を configurations::includePath に設定していた.
解決策
一度 .vscodeのフォルダを削除して作りなおしたら治った.
結論
よくわからないけどやり直しが一番